The last few blog posts explored the topic of counting unique items efficiently using two specific sketching techniques – HyperLogLogs (HLLs) and KMinHash. The underlying motivation of these techniques was to use probabilistic data structures for counting high cardinality data sets, with a focus on being efficient in both time and space, trading off some accuracy in the counts. For high cardinality data sets, this is a reasonable tradeoff in some domains. We saw how HLLs in Redis provided unique counts with an error of about 0.18% with a bounded 12KB memory size per key. We also saw how well additional operations like unions and intersections fared with HLLs, and how KMinHash provided a more accurate measure over HLLs for intersection operations.
One of the strong advantages of sketching techniques is their efficiency vis-a-vis time and space system measures. Therefore, while we concluded that KMinHash provided more accurate results over HLLs for intersections, it would be good to set it in context alongside a performance comparison so that tradeoffs can be made between accuracy and performance. The purpose of this blog post is to cover the system performance measures of the two methods, using Redis as a store for the counts.
Context for the performance tests
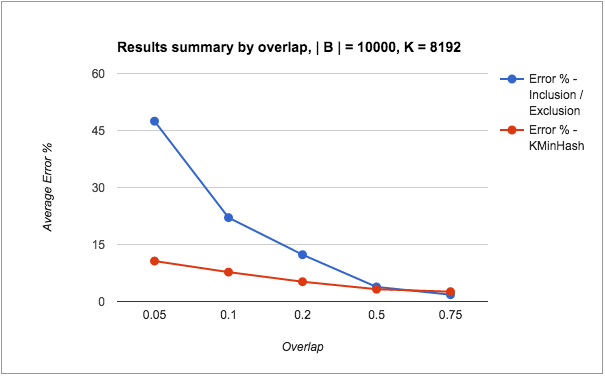
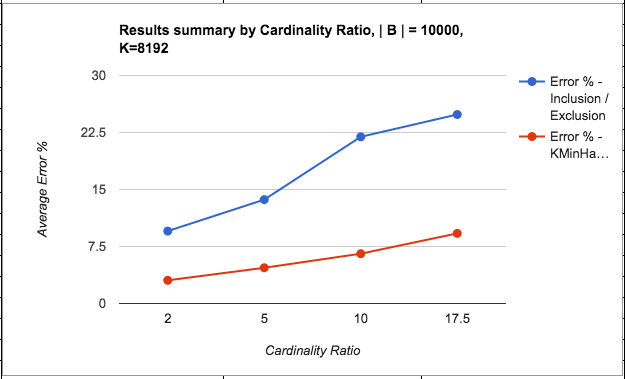
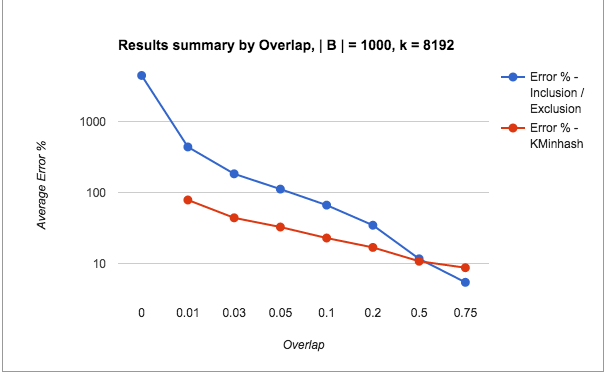
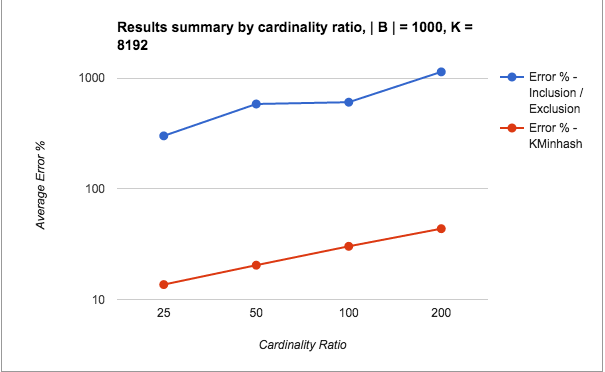
All tests involved two sets: Set A: 175,000 elements, Set B: 10,000 elements, and their intersection Set A n B: 7,500 elements. The elements were added to Redis data structures using Python client code.
The test code operated in two phases. The first added the elements to keys representing the HLL and KMinHash sets. Once all additions were completed, the second phase computed the intersection cardinality using HLL Inclusion/Exclusion principle and the KMinHash method, respectively. The details of the HLL based implementation have been covered in the first and second posts. The KMinHash algorithm has been covered in the third post. Readers can review those posts to familiarise themselves with the details.
The tests were performed on a MacBook Pro 1.6 GHz Intel Core i5 processor, 4 GB 1600 MHz DDR3 RAM. Redis version was 3.0.3 compiled from source, and started with default configuration (at least, as far as the performance related configuration goes). The test code used Python Redis client 2.10.3.
Implementation details
Counting with HLLs
For HLLs, the add phase used PFADD with Redis pipeline mechanism, and a pipeline batch size of 10,000. The compute phase merged the HLL keys using PFMERGE to compute A u B and then computed the intersection count using the Inclusion/Exclusion principle.
Here’s how the add phase looks like:
Counting with KMinHash
For KMinHash, recall that the algorithm was implemented using Redis sorted sets storing the IDs as items in the set sorted according to their hashes (which acted as scores). The add phase added/updated elements in the Redis sorted sets. The compute phase computed the Jaccard coefficient estimate using the algorithm described in post 3, and from there computed A n B cardinality.
At the time of computing the Jaccard coefficient, we should only consider the ‘k’ minimum values of the MinHash sets. However, the sets may have more than ‘k’ elements during the add phase. This gives us a knob to tradeoff between time and memory. For example, we could either keep exactly ‘k’ elements at all times thereby making sure that memory is bounded. This does require more operations in the add phase to ensure the cardinality is maintained (via a ZREM operation, for instance). The motivation to keep the memory bounded might come if we need to maintain a lot of such MinHash sets (say, for different dimensions being measured) and cumulatively, the amount of memory might shoot up very high. On the other hand, we could allow the memory to be slightly unbounded, but make the add operation very fast. This could be a valid strategy if the number of additions is going to happen very fast and saving on time is crucial.
Based on the above choices, I tried three different approaches for implementing KMinHash.
- Optimise for time (time-optimised): Add multiple elements as a batch using the Redis pipeline mechanism, and truncate the batch to the size of ‘k’ once we have added the batch. Note that in this approach, the MinHash set’s size could grow beyond ‘k’ (depending on the size of the batch).
Here’s how the add phase looks using batch addition. Note the cardinality adjustment at the end of the batch.
- Optimise for memory (mem-optimised): Bound the cardinality of the KMinHash sets to ‘k’ at add time itself. We do this by truncating the MinHash set to ‘k’ elements after any addition that potentially increases the set’s size. We maintain some state on the client – the current cardinality of the sorted set and the current max MinHash value. This state acts as a cache to help avoid some calls to the Redis server.
This is how the mem-optimised version looks. Note the cardinality adjustment after every add post ‘k’ elements. The local state is maintained in variables like elements_added and max_min_hash
- Server side scripting (scripting): Redis has a mechanism to execute something akin to stored procedures of a database, by writing them using the LUA scripting language. In this method, define a LUA script that updates the KMinHash set keeping the cardinality bounded to ‘k’. Call this script in pipeline mode during the add phase using the Redis command EVAL or EVALSHA.
Here’s the Lua script that is loaded and executed in the Redis server process. Note how the cardinality is adjusted after every addition post ‘k’ elements. The difference with the mem-optimised approach is that all state is maintained in Redis itself.
The native support for HLL in Redis acts as an advantage and it should be intuitively clear that HLLs score better than KMinHash overall. So, this is not really to show whether KMinHash is better than HLL (which it is not), but to illustrate the comparative system measures for similar cardinality sets in both approaches, as also among the various KMinHash implementation strategies.
Time comparison
Things to measure here included the time indicators between HLL and KMinHash implementations, and also across the various KMinHash implementations. To compare various KMinHash implementations, the high level ‘time’ command was used. The tests were run multiple times to see stability of the time measures across different data sets. The results of the same are as below:
- KMinHash – time-optimised: 8.5 seconds (average real time)
- KMinHash – mem-optimised: 13.85 seconds (average real time)
- KMinHash – scripting: 11.2 seconds (average real time)
Note that this time includes the add phase and compute phase; however, since the HLL addition and cardinality computation is fixed, the time difference is only accounted for by the various KMinHash strategies used.
To compare times between HLL and KMinHash specifically, the Python profiler cProfile was used and the cumulative time measured across individual calls. The results are as below:
- HLL addition: 6.1 seconds
- KMinHash addition – time-optimised: 7.2 seconds
- KMinHash addition – mem-optimised: 12.9 seconds
- KMinHash addition – scripting: 10.2 seconds
- HLL intersection: 0
- KMinHash intersection – time-optimised: 0.03 seconds
- KMinHash intersection – mem-optimised: 0.04 seconds
- KMinHash intersection – scripting: 0.02 seconds
Note that the times in the profiled runs don’t add up exactly to the measurements using the ‘time’ command. I suspect this could be due to the profiler overhead.
From the above, we can draw the following conclusions:
- As expected, HLL performance is the best among all approaches in terms of time measures.
- The best performance among KMinHash approaches is from the time-optimised approach, followed by the Lua scripting approach and finally by the mem-optimised approach. This is as expected.
- The time-optimised approach is slower than the HLL approach by about 18%. In comparison, the slowest KMinHash approach (mem-optimised) is almost 100% slower.
- The time difference for intersection computation is not significant to consider and hence additions is what should be considered for selecting an approach.
Memory comparison
In terms of memory, HLL is a very efficient data structure compared to sorted sets. There are probably parameters that can be tuned for optimising set memory as well, but these will likely cause some increased load on processing time. I did not consider this in my tests.
One thing to note is that the memory is bounded in both cases after the addition of all elements: 12KB for HLL, memory for max ‘k’ elements in KMinHash. The length of the objects used can be determined using the redis command DEBUG OBJECT <key-name>. The results after adding elements from a representative dataset to both HLL and KMinHash keys are as follows:
-
HLL key 175000 size: Serialized length 10491 bytes
-
HLL Key 10000 size: Serialized length 8526 bytes
-
KMinHash key 1 size: Serialized length 187530 bytes
-
KMinHash key 2 size: Serialised length 179048 bytes
One other thing that is relevant is how the memory grows as elements are added to the sets, as these spikes can cause pressure on Redis server memory when there are a lot of such sets. Referring to the various approaches for KMinHash, we see that the time-optimised approach can add more than ‘k’ elements as they are added in batches. To measure this, I ran the redis command INFO periodically and monitored the used_memory_peak_human value as the add phase was in progress. The results are as follows:
- KMinHash – time-optimised: 67.2 MB
- KMinHash – mem-optimised: 62.2 MB
- KMinHash – scripting: 62.1 MB
With the Lua scripting technique, there is also an increase in the Lua memory used by Redis (used_memory_lua) to about 50176 bytes compared to the default of 36864 bytes.
My first implementation of the time-optimised technique adjusted the cardinality of the KMinHash set to ‘k’ only when the intersection cardinality was computed (sort of a lazy approach), instead of adjusting it after every batch addition. With this approach, the used_memory_peak_human value rose as high as 125.86 MB.
From the above, we can draw the following conclusions:
- Memory used by KMinHash is an order of magnitude more than that used by HLL.
- The mem-optimised approach is only marginally better in used_memory_peak compared to the time-optimised approach.
- A lazy time-optimised approach that clears memory only at the end of the add phase does significantly increase memory consumption – almost 100% more than the optimised cases.
Conclusion
HLL is superior to KMinHash based implementations by a reasonable margin from a performance perspective, which is expected given that it is a highly optimised implementation in the Redis server. However, for the accuracy gains of KMinHash, the penalty doesn’t seem too high. Given that the time-optimised approach gives the best time performance, with only marginally weaker memory performance, it is possibly the best implementation overall for KMinHash. So, it could well be something that is implemented along side HLLs to provide an efficient and accurate unique value counting solution in a BigData analytics system.
While I have tried to optimise the code as much as I could, I might not have got everything completely right, as my Redis knowledge isn’t too high. If anyone has suggestions to improve this implementation, or alternate ideas, I request readers to please post those in comments for the benefit of all.